梯度|北大校友“炼丹”分享:OpenAI如何训练千亿级模型?( 五 )
switch transformer论文总结了用于训练大型模型的不同数据和模型并行策略,并给出了一个很好的示例: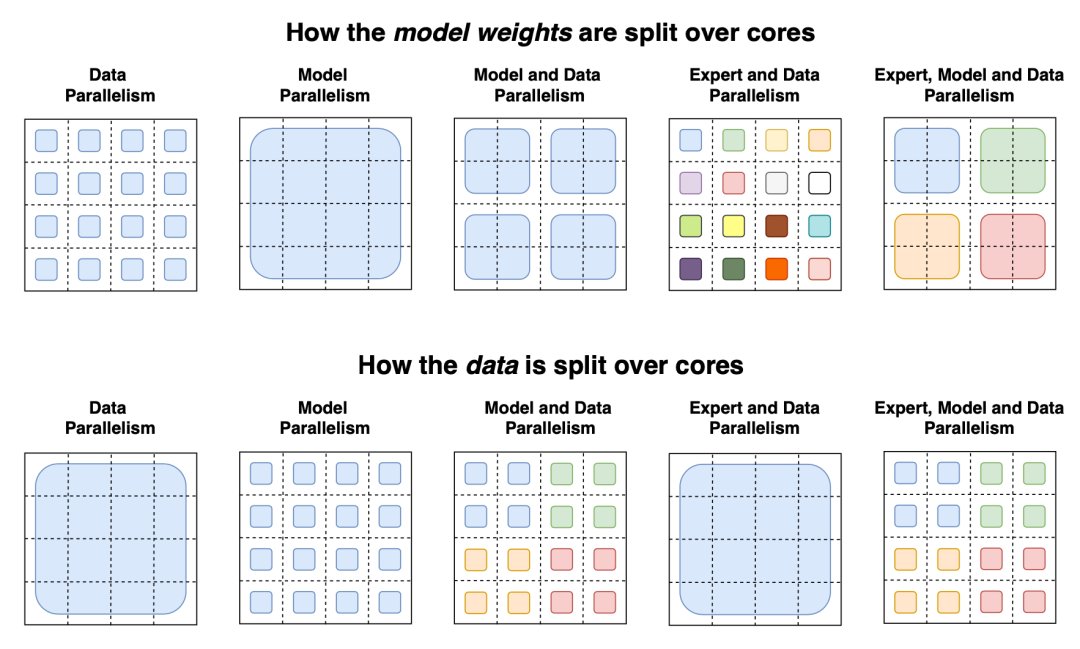
文章插图
图14:第一行为如何在多个GPU内核拆分模型权重(顶部),每种颜色代表一个权重矩阵;第二行为各种数据并行策略的说明,不同颜色表示不同的标记集(来源:Fedus等人,2021年)
如果GPU内存已满,可以将暂时未使用的数据卸载到CPU,并在以后需要时将其读回(Rhu等人,2016)。不过,这种方法近年来并不太流行,因为它会延长模型训练的时间。
激活重新计算
激活重新计算,也称“激活检查点”或“梯度检查点”(Chen et al,2016),其核心思路是牺牲计算时间来换取内存空间。它减少了训练 ? 层深层神经网络到的内存开销,每个batch只消耗额外的前向传递计算。
具体来说,该方法将?层网络平均划分为d个分区,仅保存分区边界的激活,并在workers之间进行通信。计算梯度仍然需要在分区内层进行中间激活,以便在向后过程中重新计算梯度。在激活重新计算的情况下,用于训练M(?) 是:
文章插图
它的最低成本是:
激活重新计算的方法可以得出与模型大小有关次线性内存开销,如下图: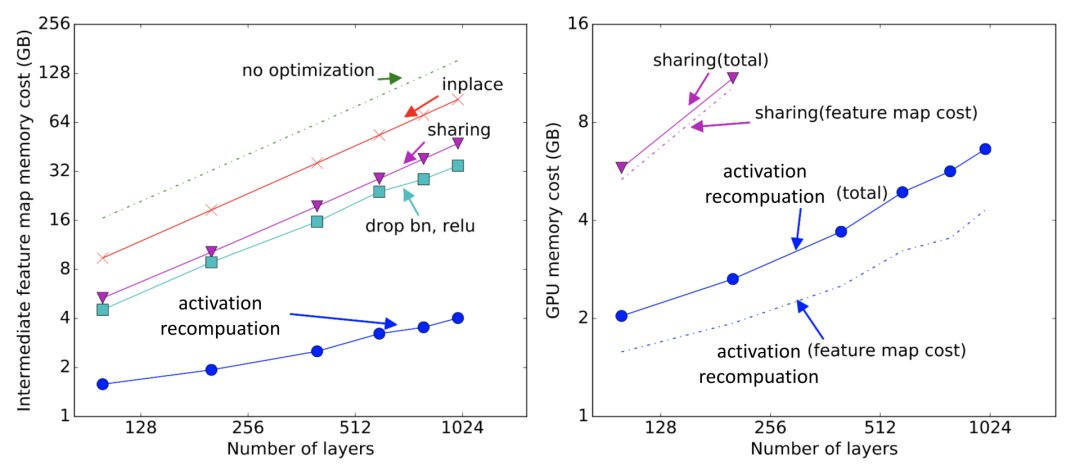
文章插图
图15:不同节省内存算法的内存开销。sharing:中间结果使用的内存在不再需要时被回收。inplace:将输出直接保存到输入值的内存中(来源:Chen等人,2016)
此前,Narang(Narang&Micikevicius;等人,2018年)介绍了一种使用半精度浮点(FP16)数训练模型而不损失模型精度的方法。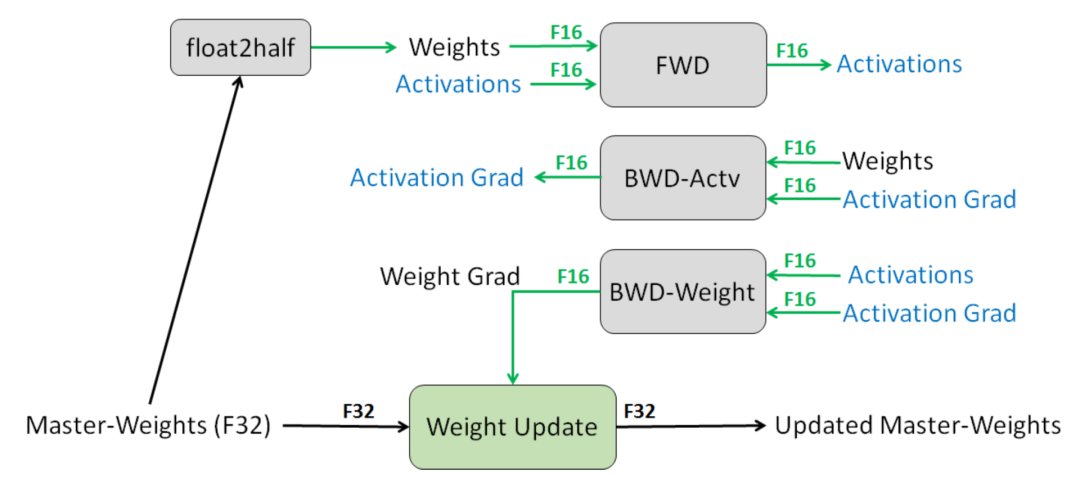
文章插图
图16:一层混合精度训练程序(来源:Narang&Micikevicius;等人,2018年)
其中涉及三种关键技术:
- 全精度权重复制:保持累积梯度的模型权重的全精度(FP32)复制。对于向前和向后的传递的信息做四舍五入至半精度处理,因为每次梯度更新(即梯度X学习率)太小,可能无法完全包含在FP16范围内。
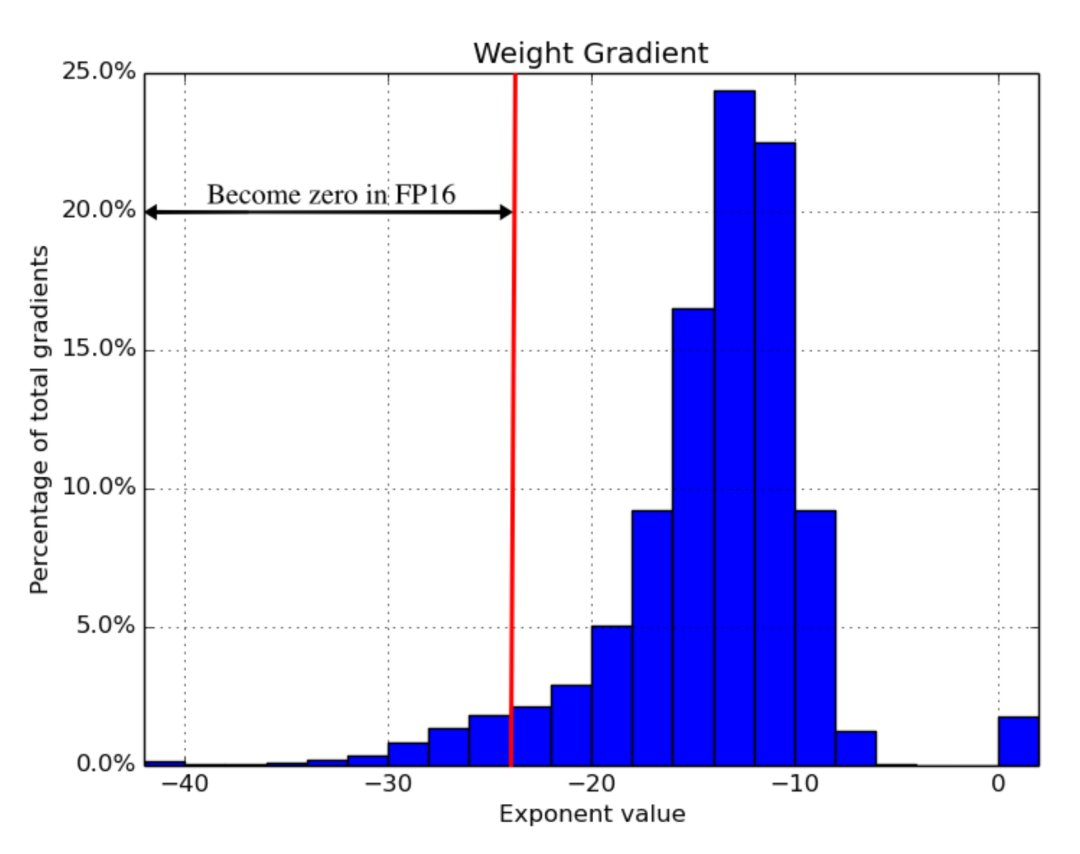
- 缩放损失:放大损失以更好地处理小幅度的梯度(见图16),放大梯度以使其向可表示范围的右侧部分(包含较大的值)移动,从而保留可能丢失的值。
- 算术精度:对于常见的网络算法(如矢量点积、矢量元素求和归约),将部分结果累加到FP32中,然后输出保存为FP16。逐点操作可以在FP16或FP32中执行。
文章插图
在这项实验中,图像分类、更快的R-CNN等不需要损失缩放,但其他网络,如多盒SSD、大LSTM语言模型是需要损失缩放的。
压缩(Compression)
模型权重在向前和向后传递的过程中会消耗大量内存。考虑到这两种传递方式会花费大量时间,2018年Jain (Jain et al,2018)提出了一种数据编码策略,即在第一次传递后压缩中间结果,然后将其解码用于反向传播。
Jain和团队研发的Gist系统包含两种编码方案:一是特定于层的无损编码,包括 ReLU-Pool和 ReLU-Conv模式;二是有攻击性的有损编码,主要使用延迟精度缩减(DPR)。需要注意的是,第一次使用特征图时应保持高精度,第二次使用时要适度降低精度。这项实验表明,Gist可以在5个最佳图像分类DNN上减少2倍的内存开销,平均减少1.8倍,性能开销仅为4%。
- 单项冠军|再添三家“小巨人”,青岛高新区梯度培育见成效
- 飞利浦·斯塔克|第一名!北大才子郭资政将会国产EDA产业带来希望
- 杨振宁北大演讲大谈“天才”,却只字不提爱因斯坦,为什么?
- 前谷歌大脑科学家称梯度下降为机器学习中最优雅idea,LeCun大赞
- 数学|今年高考数学难被吐槽 网传北大韦神点评:考个140分很轻松
- 北大“韦神”接受采访,回答找女友的意愿,答案让众人笑开了花!
- LeCun称梯度下降是最优雅的 ML 算法,Marcus:我不同意
- 高考|俞敏洪考上北大是偶然:原因揭开
- 保安|27年前考上北大的保安:如今成为校长送考
- 第一名|北大学子立功了,斩获国际竞赛第一名,突破EDA芯片设计难题