梯度|北大校友“炼丹”分享:OpenAI如何训练千亿级模型?( 二 )

文章插图
模型并行
模型并行(Model parallelism,MP)用于解决模型权重不能适应单个节点的情况,在这里,计算和模型参数都需要跨多台机器进行处理。在数据并行中,每个worker承载着整个模型的完整副本,而MP只在一个worker上分配部分模型参数,因此对内存和计算的需求要小很多。
深度神经网络包含一堆垂直层,如果逐层拆分将连续的小层分配到工作层分区,操作起来并不难,但通过大量具有顺序依赖性的Workers来运行每个数据batch会花费大量的时间,计算资源的利用率也严重不足。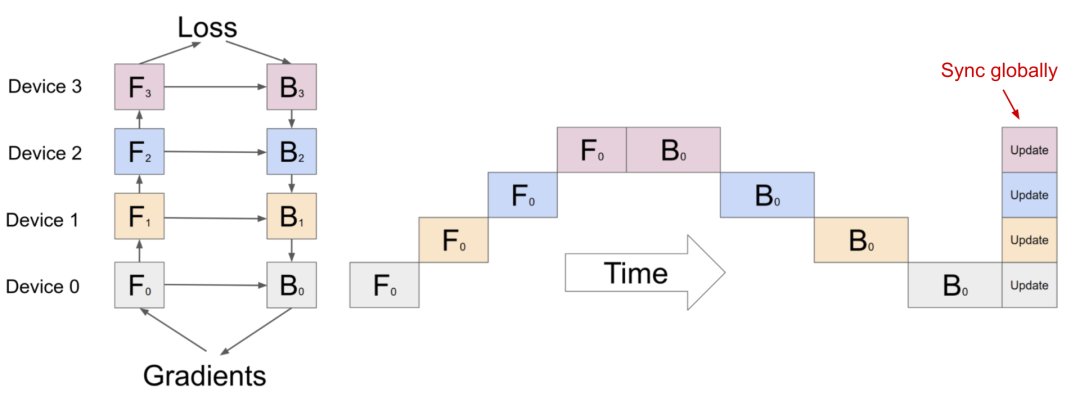
文章插图
管道并行
管道并行(Pipeline parallelism,PP)是将模型并行与数据并行结合起来,以减少低效时间“气泡”的过程。主要思想是将Mini-batch拆分为更多个微批次(microbatch),并使每个阶段worker能够同时处理。需要注意的是,每个微批次需要两次传递,一次向前,一次向后。worker分区的数量称为管道深度,不同worker分区之间的通信仅传输激活(向前)和梯度(向后)。这些通道的调度方式以及梯度的聚合方式在不同的方法中有所不同。
在GPipe(Huang et al.2019)方法中,多个微批次处理结束时会同时聚合梯度和应用。同步梯度下降保证了学习的一致性和效率,与worker数量无关。如图3所示,“气泡”仍然存在,但比图2少了很多。给定m个均匀分割的微批次和d个分区,假设每个微批次向前和向后都需要一个时间单位,则气泡的分数为: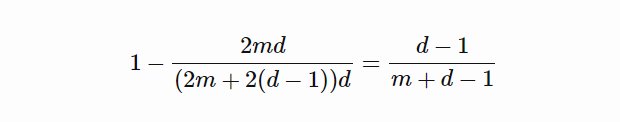
文章插图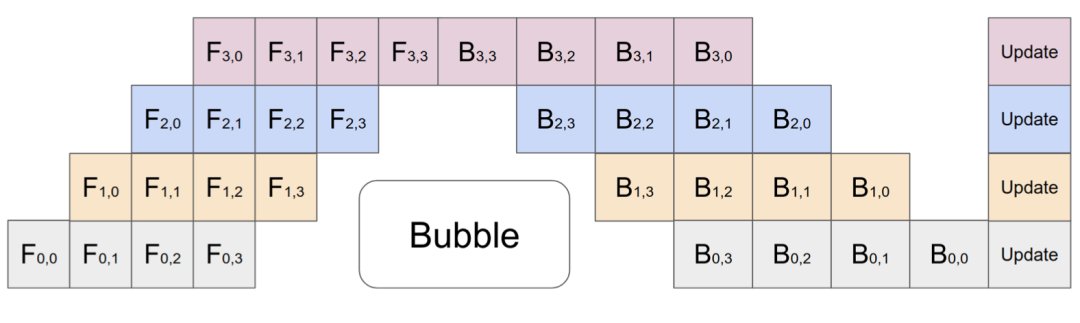
文章插图
GPipe在吞吐量方面与设备数量成线性关系,设备数量越多,吞吐量越大。不过,如果模型参数在worker中分布不均匀,这种线性关系不会稳定出现。
PipeDream(Narayanan等人,2019年)方法要求每个worker交替处理向前和向后传递的消息(1F1B)。它将每个模型分区命名为“stage”,每个stage worker可以有多个副本来并行运行数据。这个过程使用循环负载平衡策略在多个副本之间分配工作,以确保相同minibatch 向前和向后的传递发生在同一副本上。 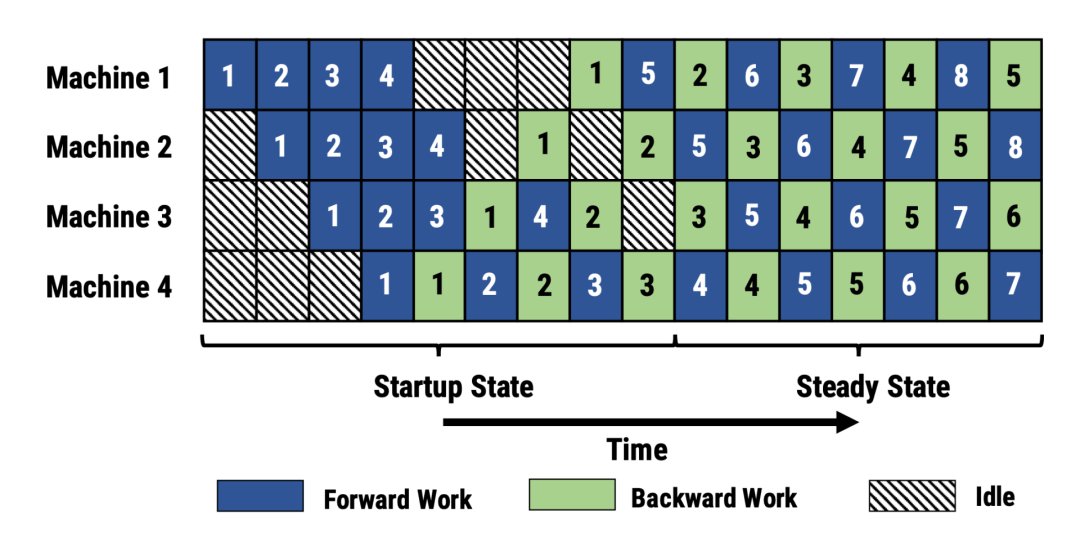
文章插图
由于PipeDream没有在所有worker batch结束时同步全局梯度,1F1B 很容易导致不同版本的模型权重的微批次向前和向后传递,降低学习效率。对此,PipeDream提供了一些解决的思路:
- 权重存储:每个worker跟踪多个模型版本,给定数据 batch 的向前和向后传递相同版本的权重。
- 垂直同步:不同模型权重版本与激活和梯度一起在全局worker之间传递,计算采用上一个worker传播的相对应的隐藏版本。这个过程确保了worker之间的版本一致性(不同于GPipe,采用异步计算)。
- 单项冠军|再添三家“小巨人”,青岛高新区梯度培育见成效
- 飞利浦·斯塔克|第一名!北大才子郭资政将会国产EDA产业带来希望
- 杨振宁北大演讲大谈“天才”,却只字不提爱因斯坦,为什么?
- 前谷歌大脑科学家称梯度下降为机器学习中最优雅idea,LeCun大赞
- 数学|今年高考数学难被吐槽 网传北大韦神点评:考个140分很轻松
- 北大“韦神”接受采访,回答找女友的意愿,答案让众人笑开了花!
- LeCun称梯度下降是最优雅的 ML 算法,Marcus:我不同意
- 高考|俞敏洪考上北大是偶然:原因揭开
- 保安|27年前考上北大的保安:如今成为校长送考
- 第一名|北大学子立功了,斩获国际竞赛第一名,突破EDA芯片设计难题