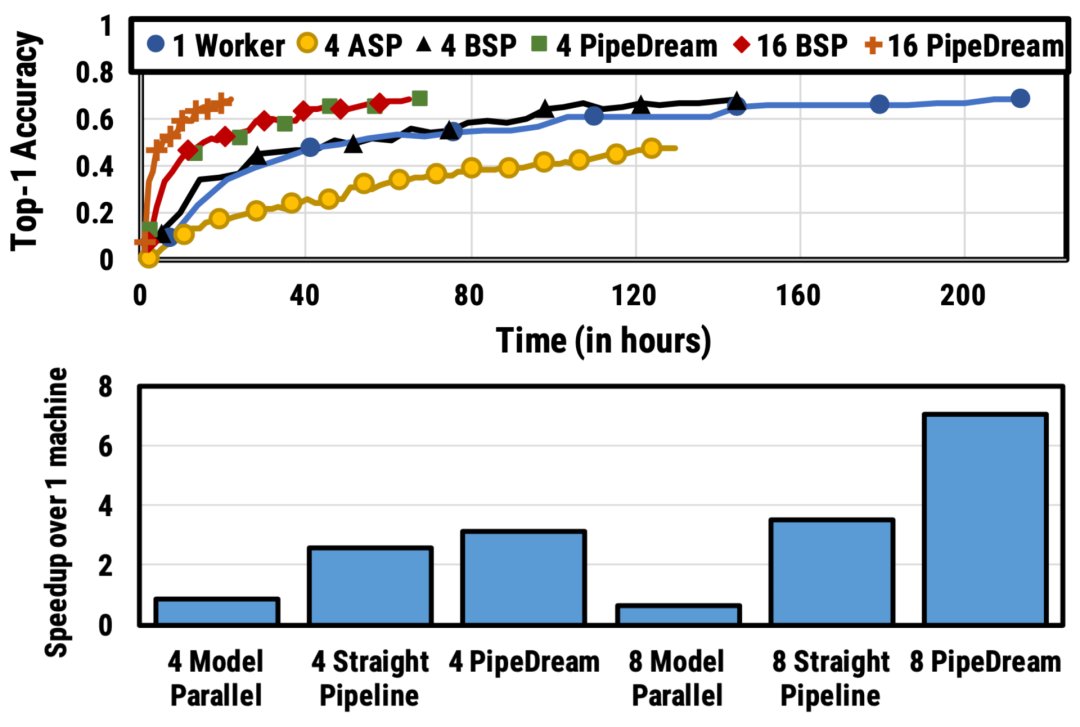
梯度|北大校友“炼丹”分享:OpenAI如何训练千亿级模型?( 三 )
文章插图
后来有学者提出了PipeDream两种变体,主要思路是通过减少模型版本来缓解内存占用(Narayanan等人,2021年)。其中,PipeDream-flush增加了定期刷新全局同步管道的功能,就像GPipe一样,这种方式虽然牺牲了一点吞吐量,但显著减少了内存占用(例如仅需要维护单一版本的模型权重)。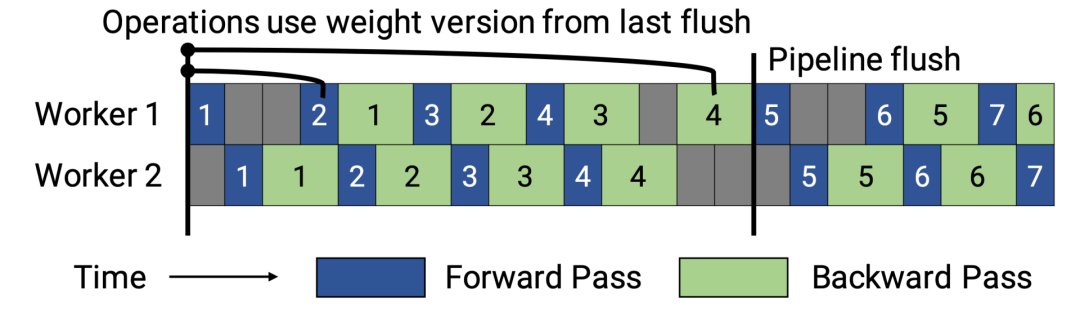
文章插图
图6:PipeDream flush中管道调度图示(来源:Narayanan等人,2021年)
PipeDream-2BW维护两个版本的模型权重,“2BW”代表“双缓冲权重(double-buffered weights)”,它会在每个微批次生成一个新的模型版本K(K>d)。由于一些剩余的向后传递仍然依赖于旧版本,新的模型版本无法立即取代旧版本,但因为只保存了两个版本,内存占用的也被大大降低了。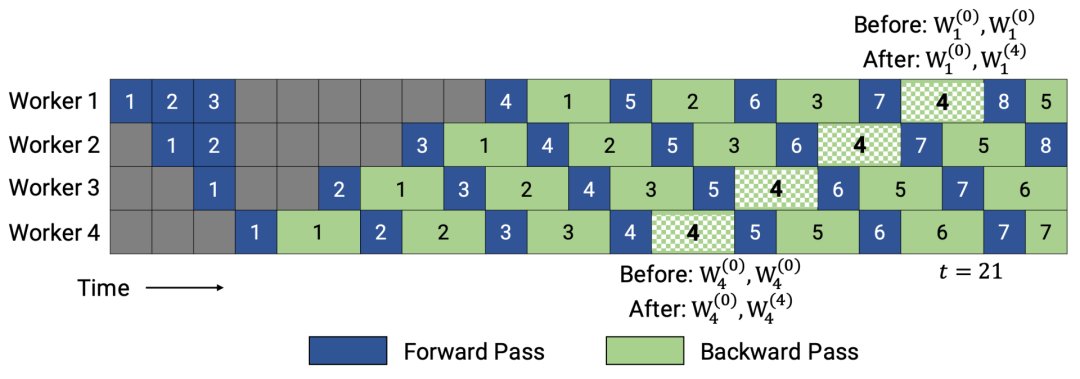
文章插图
张量并行
模型并行和管道并行都会垂直拆分模型,而张量并行(Tensor Parallelism,TP)是将张量运算的计算水平划分到多个设备上。
以Transformer为例。Transformer架构主要由多层MLP和自注意力块组成。Megatron-LM(Shoeybi et al.2020)采用了一种简单的方法来并行计算层内MLP和自注意力。
MLP层包含GEMM(通用矩阵乘法)和非线性GeLU传输。如果按列拆分权重矩阵A,可以得到:
文章插图
注意力块根据上述分区并行运行GEMM的 查询(Q)、键(K)和 权重(V),然后与另一个GEMM组合以生成头注意力结果。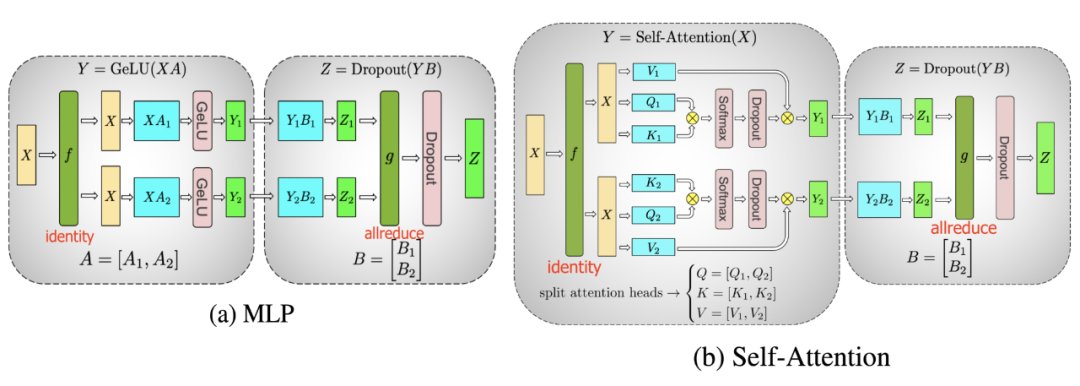
文章插图
今年Narayanan等人将管道、张量和数据并行与新的管道调度策略相结合,提出了一种名为PTD-P的新方法。该方法不仅在设备上能够定位一组连续的层(“模型块”),该可以为每个wokers分配多个较小的连续层子集块(例如,设备1具有第1、2、9、10层;设备2具有第3、4、11、12层;每个具有两个模型块)
每个batch中,微批次的数量应精确除以wokers数量(mm)。如果每个worker有v个模型块,那么与GPipe调度相比,管道的“气泡”时间可以减少 v 倍。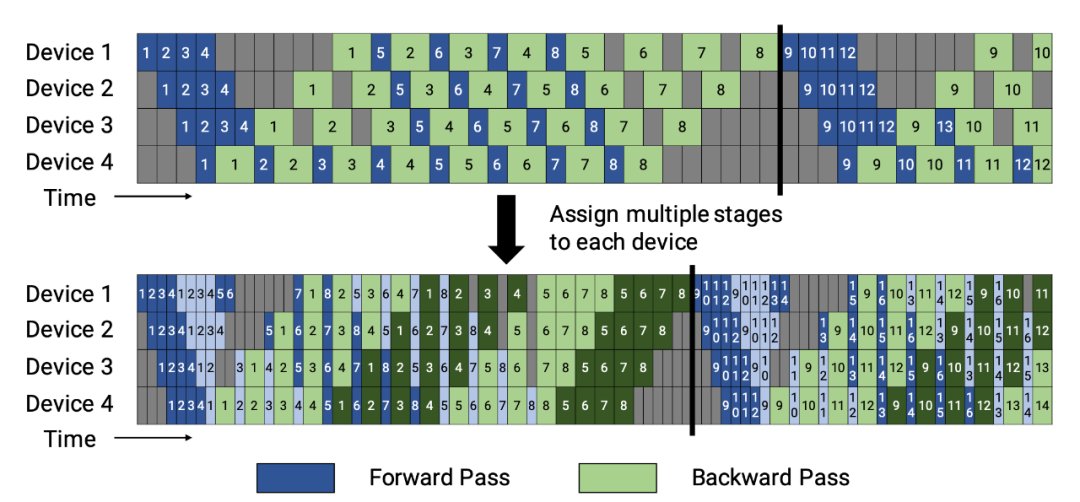
文章插图
图9:上图与PipeDream flush中的默认1F1B管道明细表相同;下图为交错的1F1B管线一览表(来源:Narayanan等人,202)
在深度神经网络中,混合专家(MoE)通过连接多个专家的门机制(gating mechanism)实现集成(Shazeer等人,2017)。门机制激活不同网络的专家以产生不同的输出。作者在论文将其命名为“稀疏门控专家混合层(sparsely gated MoE)”。
仅一个MoE层包含:(1)前馈网络专家n;(2)可训练的门控网络G,通过学习n个专家的概率分布,将流量路由到几个特定的专家。
- 单项冠军|再添三家“小巨人”,青岛高新区梯度培育见成效
- 飞利浦·斯塔克|第一名!北大才子郭资政将会国产EDA产业带来希望
- 杨振宁北大演讲大谈“天才”,却只字不提爱因斯坦,为什么?
- 前谷歌大脑科学家称梯度下降为机器学习中最优雅idea,LeCun大赞
- 数学|今年高考数学难被吐槽 网传北大韦神点评:考个140分很轻松
- 北大“韦神”接受采访,回答找女友的意愿,答案让众人笑开了花!
- LeCun称梯度下降是最优雅的 ML 算法,Marcus:我不同意
- 高考|俞敏洪考上北大是偶然:原因揭开
- 保安|27年前考上北大的保安:如今成为校长送考
- 第一名|北大学子立功了,斩获国际竞赛第一名,突破EDA芯片设计难题