梯度|北大校友“炼丹”分享:OpenAI如何训练千亿级模型?( 四 )
根据门控输出,并非每个专家都必须进行评估。当专家的数量太大时,可以考虑使用两层MoE。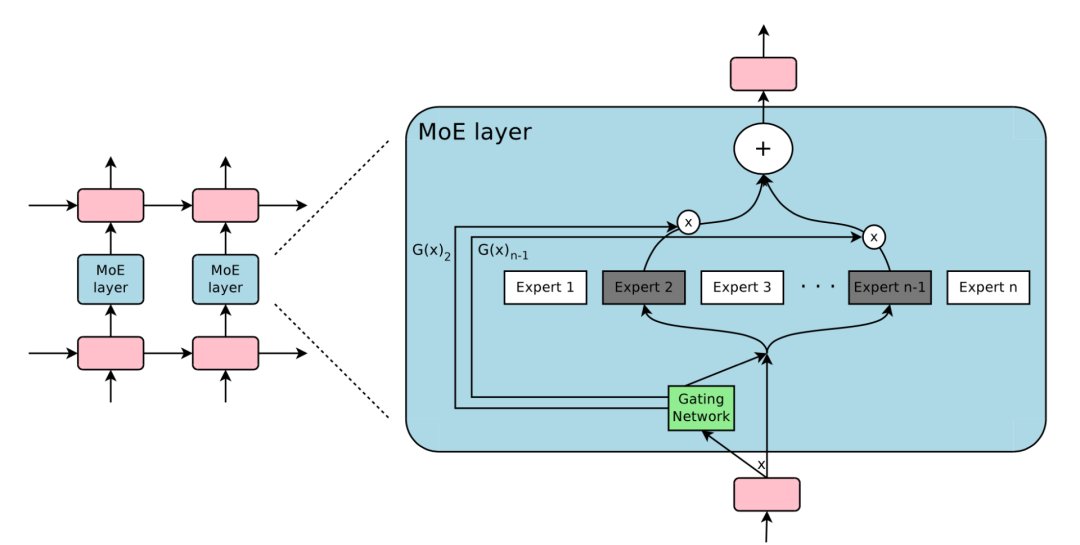
文章插图
图10:专家混合(MoE)层的图示,门控网络只选择并激活了n个专家中的2个(来源:Shazeer等人,2017年)
由于这个过程会产生密集的门控制向量,不利于节省计算资源,而且时也不需要评估专家。所以,MoE层仅保留了顶部k值,并通过向G中添加高斯噪声改进负载平衡,这种机制被称为噪声top-k门。
文章插图
其中,CV是变异系数,失重的waux是可调节的超参数。由于每个专家网络只能获得小部分训练样本(“收缩批次问题”),所以在MoE中应该尽可能使用大batch,但这又会受到GPU内存的限制。数据并行和模型并行的应用可以提高模型的吞吐量。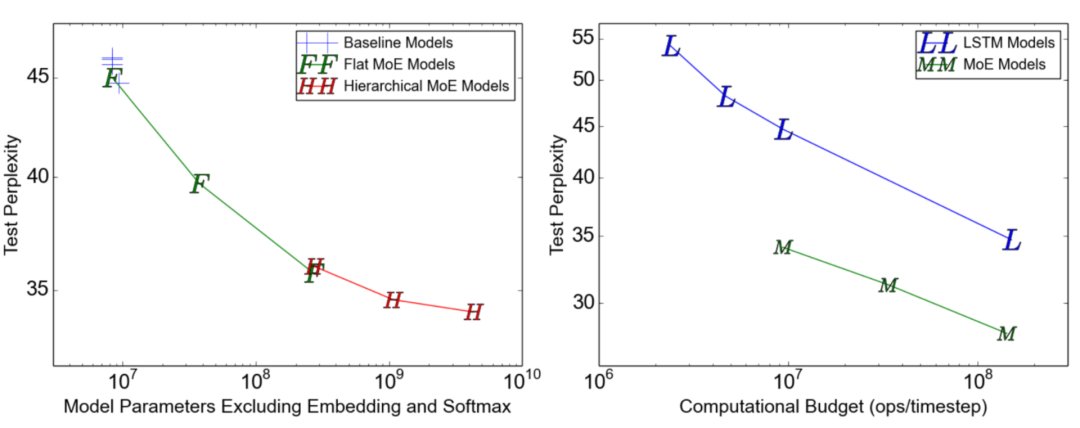
文章插图
GShard(Lepikhin等人,2020年)通过自动分片将MoE transformer 模型的参数扩展到了6000亿。MoE transformer 用MoE层取代其他每一个前馈网络层。需要说明的是,在多台机器上MoEtransformer 仅在MoE层分片,其他层只是复制。
GShard中的门控功能G有几种改进设计:
- 专家容量:通过一位专家的令牌数量不应超过“专家容量”的阈值。如果令牌被路由到已达到容量的专家,则令牌将被标记为“溢出”,并且门输出将更改为零向量。
- 本地组调度:令牌被均匀地划分为多个本地组,专家能力在组水平上得到加强。
- 辅助损失:与原始MoE aux损失相似,添加辅助损失可以最小化路由到每个专家的数据的均方。
- 随机路由:以与其权重成比例的概率选择第二位最佳专家;否则GShard遵循随机路由,增加随机性。

文章插图
Switch Transformer(Fedus et al.2021)用稀疏开关FFN层取代了密集前馈层(每个输入仅路由到一个专家网络),将模型规模扩展到数万亿个参数。负载平衡的辅助损失是,给定n个专家,fi是路由到第i个专家的令牌分数,pi是门控网络预测的专家i的路由概率。
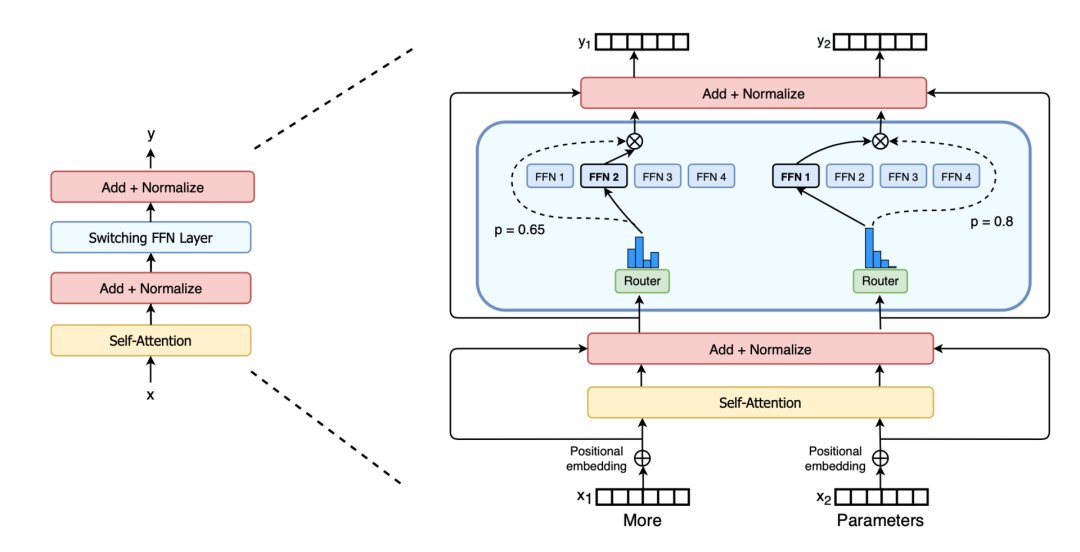
文章插图
图13:Switch transformer,稀疏Switch FFN层位于蓝色框(来源:Fedus等人,2021年)
为提高训练稳定性,switch transformer采用以下设计:
- 选择精度:使用FP32精度以提高模型局部的稳定性,并降低FP32张量的通信成本。FP32精度仅在路由器功能主体内使用,结果将还原到FP16。 较小的初始化:权重矩阵的初始化从平均μ=0且标准偏差的正态分布中采样,同时将Transformer初始化参数从s=1减小到s=0.1 。
- 使用更高的专家辍学率:微调通常适用于小数据集,增加每个专家的辍学率以避免过度拟合。他们发现,所有层中的辍学率增加会导致性能下降。在论文中,他们在非专家层中使用了0.1的辍学率,但在专家FF层中使用了0.4的辍学率。
- 单项冠军|再添三家“小巨人”,青岛高新区梯度培育见成效
- 飞利浦·斯塔克|第一名!北大才子郭资政将会国产EDA产业带来希望
- 杨振宁北大演讲大谈“天才”,却只字不提爱因斯坦,为什么?
- 前谷歌大脑科学家称梯度下降为机器学习中最优雅idea,LeCun大赞
- 数学|今年高考数学难被吐槽 网传北大韦神点评:考个140分很轻松
- 北大“韦神”接受采访,回答找女友的意愿,答案让众人笑开了花!
- LeCun称梯度下降是最优雅的 ML 算法,Marcus:我不同意
- 高考|俞敏洪考上北大是偶然:原因揭开
- 保安|27年前考上北大的保安:如今成为校长送考
- 第一名|北大学子立功了,斩获国际竞赛第一名,突破EDA芯片设计难题