数据集|无需任何标记数据,几张照片就能还原出3D物体结构,自监督学习还能这样用( 二 )
无需任何外部标记,2D还原3D关系
作者与其他模型进行了详细对比,这些模型涵盖不同的3D还原方法,包括深度图、CNN、立体像素、网格等。
在监督学习所用到的参数上,可用的包括深度、关键点、边界框、多视图4类;而在测试部分,则包括2D转3D、语义和场景3种方式。

文章插图
可以看见,绝大多数网络都没办法同时实现2D转3D、在还原场景的同时还能包含清晰的语义。
即使有两个网络也实现了3种方法,他们也采用了深度和边界框两种参数进行监督,而非完全通过自监督进行模型学习。
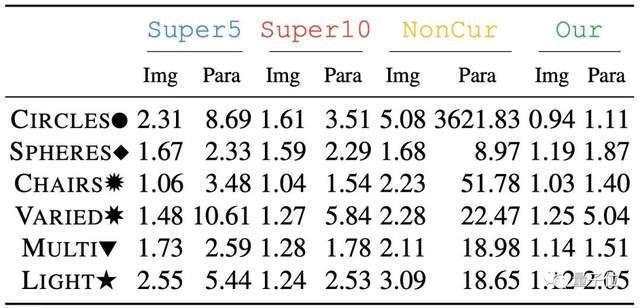
这一方法,让模型在不同的数据集上都取得了不错的效果。
无论是椅子、球体数据集,还是字母、光影数据集上,模型训练后生成的各视角照片都挺能打。

文章插图
甚至自监督的方式,还比加入5%监督(Super5)和10%监督(Super10)的效果都要更好,误差基本更低。
文章插图
而在真实场景上,模型也能还原出照片中的3D物体形状。
例如给出一只兔子的照片,在进行自监督训练后,相比于真实照片,模型基本还原出了兔子的形状和颜色。

文章插图
不仅单个物体,场景中的多个3D物体也都能同时被还原出来。

文章插图
当然,这也离不开“好奇心驱动”这种方法的帮助。
事实上,仅仅是增加“好奇心驱动”这一部分,就能降低不少参数错误率,原模型(NonCur)与加入好奇心驱动的模型(Our)在不同数据集上相比,错误率平均要高出10%以上。

文章插图
不需要任何外部标记,这一模型利用几张照片,就能生成3D关系、还原场景。
作者介绍
3位作者都来自伦敦大学学院。

文章插图
一作David Griffiths,目前在UCL读博,研究着眼于开发深度学习模型以了解3D场景,兴趣方向是计算机视觉、机器学习和摄影测量,以及这几个学科的交叉点。

文章插图
Jan Boehm,UCL副教授,主要研究方向是摄影测量、图像理解和机器人技术。
Tobias Ritschel,UCL计算机图形学教授,研究方向主要是图像感知、非物理图形学、数据驱动图形学,以及交互式全局光照明算法。
【 数据集|无需任何标记数据,几张照片就能还原出3D物体结构,自监督学习还能这样用】有了这篇论文,设计师出门拍照的话,还能顺便完成3D作业?
- 创业|八成互联网电视非法采集用户数据, 彩电企业怎么办?
- 新书推荐 │ 大数据算法设计与分析
- 肺炎患者|为何新冠患者已退烧,还需进行集中治疗
- 无人驾驶|189元Ticwatch GTK智能手表上手评测:颜值、运动、电量集一身,香
- 189元Ticwatch GTK智能手表上手评测:颜值、运动、电量集一身,香
- 微信|微信官宣:新增2大重要新功能,1个好评如潮,1个遭网友集体吐槽
- |一招教你入门数据可视化!
- 固态硬盘|PCI-E 4.0新选择,西部数据WD_BLCK SN770固态硬盘体验
- 原神|原神:说好数据互通的,为什么自己不能用电脑玩?多数人都没注意
- 客户端|多平台分析618数据,看清家居人未来方向!