研究人员|如何让人模仿猎豹走路?Stuart Russell提出基于最优传输的跨域模仿学习( 三 )
1. 当智能体域是专家域的刚性变换时,GWIL能否恢复最优行为?这是可以的,论文的作者们用迷宫证明了这一点。
2. 当智能体的状态和行动空间与专家不同时,GWIL能否恢复最优行为?这也是可以的,本篇论文中,作者们展示了倒立摆(cartpole)和钟摆(pendulum)之间轻微不同的状态-动作空间以及步行者(walker)和猎豹(cheetah)之间显著不同的空间。
为了回答这两个问题,研究人员使用了在 Mujoco 和 DeepMind 控制套件中实现的模拟连续控制任务。该学习策略的视频可在论文的项目网站上访问。在所有设置中,作者在dE和dA的专家和智能体空间中使用欧几里得度量。
学习策略地址:https://arnaudfickinger.github.io/gwil/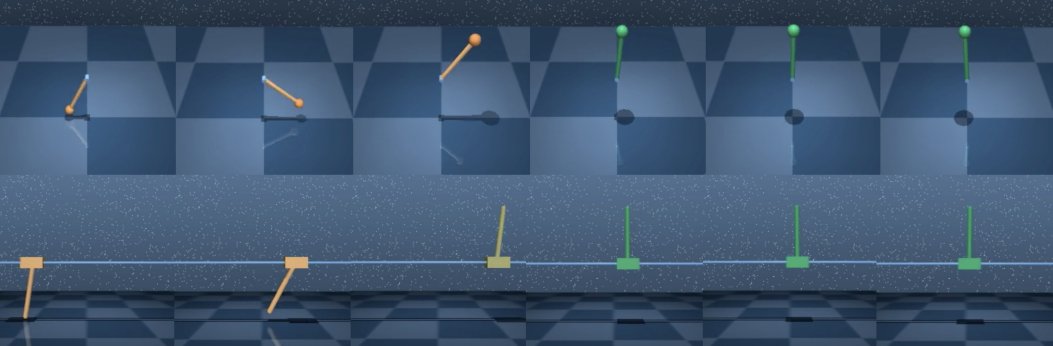
文章插图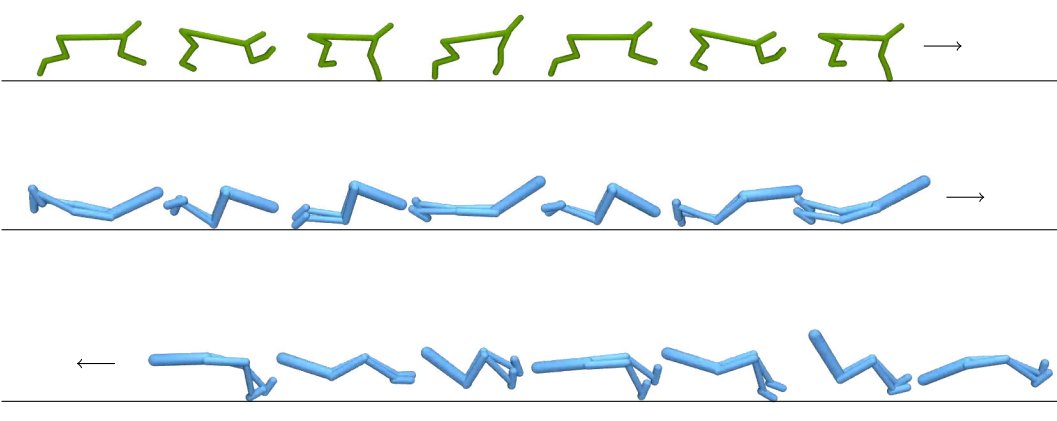
文章插图
文章插图
雷峰网
- 创投圈|抖音小店无货源适合新手小白么?如何精细化运营?新手小白看来
- 松下|淘宝店铺信誉分等级如何提升?
- PHP|如何降低用户关注的非必要页面的权重传递?
- 量子纠缠存在于任何维度空间?人类如何逃出三维空间变成“神”?
- 显卡|如何组装旗舰游戏电脑?这里有你想要的答案
- 科学家为何要在太空放火?会有什么后果?答案让人意外
- 火星和地球交换位置会如何?火星会出现生命吗?答案没你想得简单
- 快手视频|视频号和抖音快手的差异化在哪里呢?你应该如何选择适合你的平台
- AirPods|如何进行微信活动运营才有效?
- 酷睿处理器|AMD Zen4如何接招?13代酷睿Z790主板偷跑:DDR4内存还在