英伟达|中英文最大AI模型世界纪录产生,大模型竞赛新阶段来了
边策 发自 凹非寺
量子位 报道 | 公众号 QbitAI
超大AI模型训练成本太高hold不住?连市值万亿的公司都开始寻求合作了。
本周,英伟达与微软联合发布了5300亿参数的“威震天-图灵”(Megatron-Turing),成为迄今为止全球最大AI单体模型。
仅仅在半个月前,国内的浪潮发布了2500亿参数的中文AI巨量模型“源1.0”。
文章插图
不到一个月的时间里,最大英文和中文AI单体模型的纪录分别被刷新。
而值得注意的是:
技术发展如此之快,“威震天-图灵”和“源1.0”还是没有达到指数规律的预期。
要知道,从2018年开始,NLP模型参数近乎以每年一个数量级的速度在增长。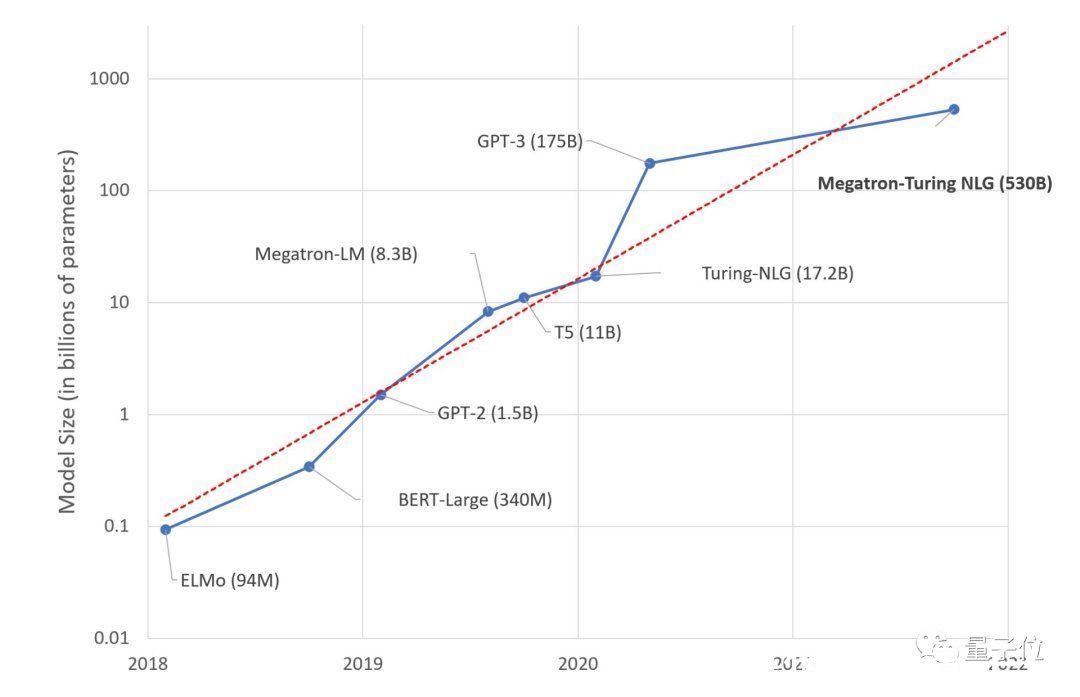
文章插图
△ 近年来NLP模型参数呈指数级上涨(图片来自微软)
而GPT-3出现后,虽然有Switch Transformer等万亿参数混合模型出现,但单体模型增长速度已经明显放缓。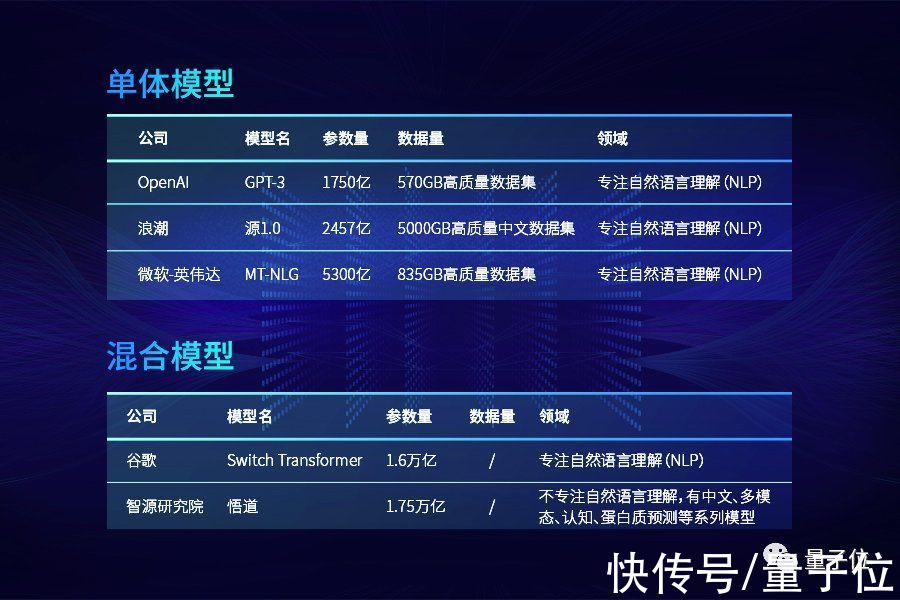
文章插图
无论是国外的“威震天-图灵”,还是国内的“源1.0”,其规模和GPT-3没有数量级上的差异。即便“威震天-图灵”和“源1.0”都用上了各自最强大的硬件集群。
单体模型是发展遇到瓶颈了么?
超大模型的三个模式回答这个疑问,首先得梳理一下近年来出现的超大规模NLP模型。
如果从模型的开发者来看,超大规模NLP模型的研发随时间发展逐渐形成了三种模式。
一、以研究机构为主导
无论是开发ELMo的Allen研究所、还是开发GPT-2的OpenAI(当时还未引入微软投资)都不是以盈利为目标。
且这一阶段的超大NLP模型都是开源的,得到了开源社区的各种复现与改进。
ELMo有超过40个非官方实现,GPT-2也被国内开发者引入,用于中文处理。
文章插图
二、科技企业巨头主导
由于模型越来越大,训练过程中硬件的优化变得尤为重要。
从2019年下半年开始,各家分别开发出大规模并行训练、模型扩展技术,以期开发出更大的NLP模型。英伟达Megatron-LM、谷歌T5、微软Turing-NLG相继出现。
文章插图
今年国内科技公司也开始了类似研究,中文AI模型“源1.0”便是国内硬件公司的一次突破——
成就中文领域最大NLP模型,更一度刷新参数最多的大模型纪录。
“源1.0”不仅有高达5TB的全球最大中文高质量数据集,在总计算量和训练效率优化上都是空前的。
三、巨头与研究机构或巨头之间相互合作
拥有技术的OpenAI由于难以承受高昂成本,引入了微软10亿美元投资。依靠海量的硬件与数据集资源,1750亿参数的GPT-3于去年问世。
但是,今年万亿参数模型的GPT-4并没有如期出现,反而是微软与英伟达联手,推出了“威震天-图灵”。
我们再把目光放回到国内。
“威震天-图灵”发布之前,国内外涌现了了不少超大AI单体模型,国内就有阿里达摩院PLUG、“源1.0”等。
像英伟达、微软、谷歌、华为、浪潮等公司加入,一方面是为AI研究提供大量的算力支持,另一方面是因为他们在大规模并行计算上具有丰富的经验。
当AI模型参数与日俱增,达到千亿量级,训练模型的可行性面临两大挑战:
1、即使是最强大的GPU,也不再可能将模型参数拟合到单卡的显存中;
2、如果不特别注意优化算法、软件和硬件堆栈,那么超大计算会让训练时长变得不切实际。
而现有的三大并行策略在计算效率方面存在妥协,难以做到鱼与熊掌兼得。
- 为什么科学家用昆虫翅膀的起源质疑进化论?达尔文到底是对是错?
- 小米Civi,推荐给喜欢高颜值外观的自拍达人
- GeForce|英伟达GeForce RTX 4090系列渲染图曝光:FE版将超过三槽规格
- 世界上最孤独的“手”,他握住一棵树长达50年,却从来没有松过手
- OPPO|OPPO真香千元机,骁龙778G+五千电池官方降至1299,好评率高达97%
- 世界智能大会|AMD7000系列V-CacheCPU与可能达到6GHz的Intel第13代抗衡
- 身份证|?电竞内存与普通内存有什么不同?金百达海力士上手体验
- 天大团队研发完全有机光驱动纳米马达,将药物定向输送到肿瘤深处
- 上海交大团队研发单结有机太阳能电池,单结器件效率达19.6%
- 固态硬盘|速率高达512GBs!PCIe7.0规范发布,但PCIe4.0或仍是主流!