机器学习|并非无所不能—评DeepMind近期神经网络求解MIP的论文( 二 )
文章插图
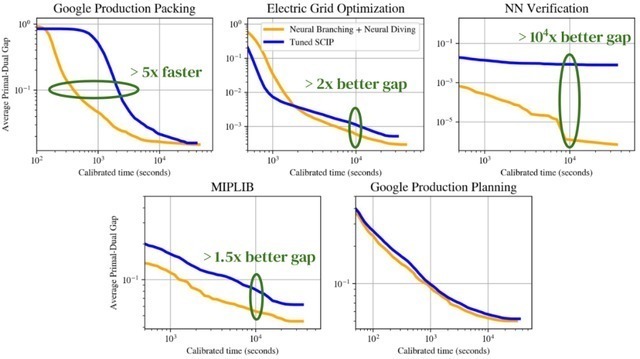
其实这里玩了一个小小的文字游戏。作为MIP求解器开发人员,一般不把一定时间内能拿到的Gap作为主要衡量标准。因为这有一定的误导性。设想一类较特殊的整数规划问题,如可行性问题,它没有目标函数,只需要找到一组整数解即可完成。那么在找到整数解之前,其Gap就是100%,找到之后就是0%。如果某个启发式(或者割平面)算法,在开启和关闭的的情况下,分别可以于1小时和3小时找到可行解。则如果以两小时为观察点,则可以说在开启这项算法的前提下,实现的Gap提升就是无穷多倍,而若以半小时或者三个小时作为观察点,则Gap没有提升。鉴于DeepMind并未公布计算这些性能指标的原始数据,我们无法用MIP业内的公认方式来对它做出评价。一般来说,根据目前公认的测试标准,一般是在MIPLIB的问题集上,以两小时为限,考虑能求解的问题数量和平均求解时间进行比较。
对于特定的测试集取得惊人的性能提升并不意外,因为这正是机器学习擅长的地方:它可以捕捉同一类问题的特征结构,并且给出优化趋势的判断。如后文所述,我们自己在开发的过程中也有类似的经历。真正值得关注的是它在MIPLIB上的表现。MIPLIB 2017 由1000多个来自各行各业的实例构成,而MIPLIB2017 Benchmark则是其中挑选的240个结构各异的问题组成,在筛选的时候就充分的做到了差异化,因此它和电网优化和NN Verification等测试集有本质的区别。这也解释了在MIPLIB上算法性能提升效果并不如其他数据集明显的原因。为了避嫌, Google也一早就在论文中表明,训练集用的是MIPLIB完整版的1000多个问题,去掉这240个问题剩余的例子。但是这依然难以避免训练集和测试集的结构相似性。例如MIPLIB 2017的完整版在收集的时候,往往会从同一个来源收集多个大小不同稍有差异的算例。在遴选测评(Benchmark)集的时候,为了避免测评集的重复性,会尽量避免使用来自同一个来源的例子,这使得MIPLIB 2017 完整版中剩下的例子包含了测评(Benchmark)集的高度结构相似问题。如MIPLIB 2017 Benchmark中有graph20-20-1rand这个问题,而在MIPLIB2017全集中有graph-20-80-1rand,graph-40-20-1rand,graph-40-40-1rand,graph-40-80-1rand四个结构高度类似的问题。因此在训练集上获得的经验,必然会对求解最后的测试集有帮助。而这些帮助能否泛化推广到任何通用问题集上,高度存疑。
分支算法与Neural Branching
分支(Branching) 算法是整数规划求解器的核心框架。求解MIP通常需要求解多个LP(线性规划)问题完成。其中第一个LP问题是原始问题去掉全部的整数约束得来。如果第一个LP问题的最优解碰巧满足整数条件,则这个解也是整数规划的最优解。如果LP松弛问题的解不都满足整数条件,则可以通过分支算法继续寻找整数解。
分支算法通过选择一个取值不为整数的变量x=x*进行分支,通过分别添加x≤floor(x*)(即取值不大于x*的最大整数下界)和x≥ceil(x*)(即取值不小于x*的最小整数上界)这两个约束来把原始问题分解为两个子问题。原整数规划问题的最优解一定在这两个分支之一。接下来继续求解这两个新的问题,并以此类推,直到找到最优的整数解或者证明整数解不存在为止。不难看出,分支算法的本质是枚举,在有n个0-1变量的混合整数规划问题里,最坏情况要遍历所有2的n次方个分支节点。也因为混合整数规划问题是个NP难问题,所以目前精确求解的算法,基本上都基于分支算法的框架,最坏情况下复杂度是指数时间级别,耗时可能会极端漫长。
- 36氪首发|烹饪机器人公司「智谷天厨」获数千万元天使轮融资,羲融善道独家投资
- 网友热议|母亲回应3个孩子2个上清华:只能教孩子做人诚实守信 学习都靠自己努力
- 机器人|华为机器人新专利上线 网友:先有华为后有天开上鸿蒙如升仙
- 金字塔是时间机器?用途是拉伸和压缩时间,或能使生命延长和衰老
- 第六届全省中小学生互联网+机器人设计活动决赛顺利结束
- “文旅机器人小i”上岗
- 文旅机器人“小i”来了
- 如何评价扫地机器人离家出走一事?
- 李飞飞团队将ViT用在机器人身上,规划推理最高提速512倍
- 格力电器|不要再说Python难了,按照这个学习路线,四周速成Python