云原生|Confluent上市与Cloudera私有化背后:从硅谷大数据公司的势力更替看数据分析的未来( 二 )
在运维成本方面,由于Hadoop的解决方案通常是从其生态中的数百个开源项目中选择一堆技术组件组合起来实现相关功能,这样的体系非常复杂,且组件间的耦合度非常高。随着Hadoop生态技术组件越来越庞杂,组件之间的耦合性和差异性要求开发和运维人员具备全栈能力,给企业带来了不菲的运维成本。
成本因素之外,业务需求的变化则在另一个层面驱动了数据分析技术的迭代。
在数仓时代,企业的数据分析需求以处理结构化数据、为业务人员作报表应用为主,MPP架构在当时能够很好地满足这些需求。
但随着互联网、移动互联网的逐步普及,企业内沉淀的数据量呈现出爆发式增长,不仅数据量本身变得很大,数据类型也从原来的结构化数据为主,发展为包含各类结构化、半结构化、非结构化,以及图片和音视频数据。MPP架构无法承接对大量非结构化和半结构化数据的处理,而Hadoop架构由于生态内具有众多组件能够实现不同功能,可以处理复杂类型的数据,其分布式架构也能够为企业实现大数据分析的高性能,以Hadoop为基础的数据湖架构兴起。
然而近年来,企业面临的数据分析业务需求也发生了重要改变,使得Hadoop越来越不能很好地满足企业日益复杂的分析需求。这些改变主要体现在三个方面:
1)随着数字化转型浪潮的推进,企业有越来越多在线化、互联网化的业务场景,上云的渗透率越来越高,大量数据的产生、采集和应用都发生在云端,而更适应本地化部署特性的Hadoop很难满足企业数据流动的需要。
2)同样随着企业数字化的深入,企业产生了大量创新性的数据应用需求,需要快速落地、快速迭代。而Hadoop架构由于过于繁重,无法适应企业对数据应用的敏捷性需求。
3)人工智能和机器学习在数据分析领域的应用正在加速落地,而一些高级的分析框架,比如TensorFlow,其分布式架构在设计之初就是基于云原生架构,没有考虑过Hadoop架构,因此在Hadoop上很难部署和运行这类高级分析框架。
02 云原生架构的浪潮已经到来既然Hadoop在面对新的数据分析需求时已经展现出种种不足,那下一代架构是什么?事实上,包括Confluent在内的新一代大数据公司已经回答了这个问题——拥抱云原生。云原生是指在应用的设计阶段就为了云的运行环境而设计,包含微服务、容器化、DevOps、持续交付等特征,充分利用和发挥云平台的弹性和分布式架构的优势。
由于意识到企业用户的需求正在往云端、存储计算分离、敏捷等方向上发展,一些领先的大数据公司早在几年前就将重点放在了云原生版本的产品上,也由此获得了显著的成功。
以刚刚IPO的Confluent公司为例,其所代表的开源流数据工具Kafka最早也是源自于Hadoop生态。Kafka为不同数据源之间数据的交换这个任务而生,Confluent将Kafka商业化推出Confluent Platform并取得了成功,随后在2018年推出了云原生的版本Confluent Cloud,为用户提供完全托管的云端服务,具备弹性伸缩以及支持用户敏捷开发等特性。
根据Confluent招股说明书,Confluent Cloud在2020年取得了3140万美元的订阅收入,2019年、2020年和2021年前3个月的增速分别达到454%、117%和124%。尽管Confluent Cloud的收入目前仅占到公司总收入的20%左右,但其表现出的成长性远超本地产品Confluent Platform约50%的增速。Confluent在招股说明书中也强调了公司云原生的战略,并将Confluent Cloud视为公司未来收入增长的最重要产品。这应该也是资本市场给与Confluent高度认可的主要原因。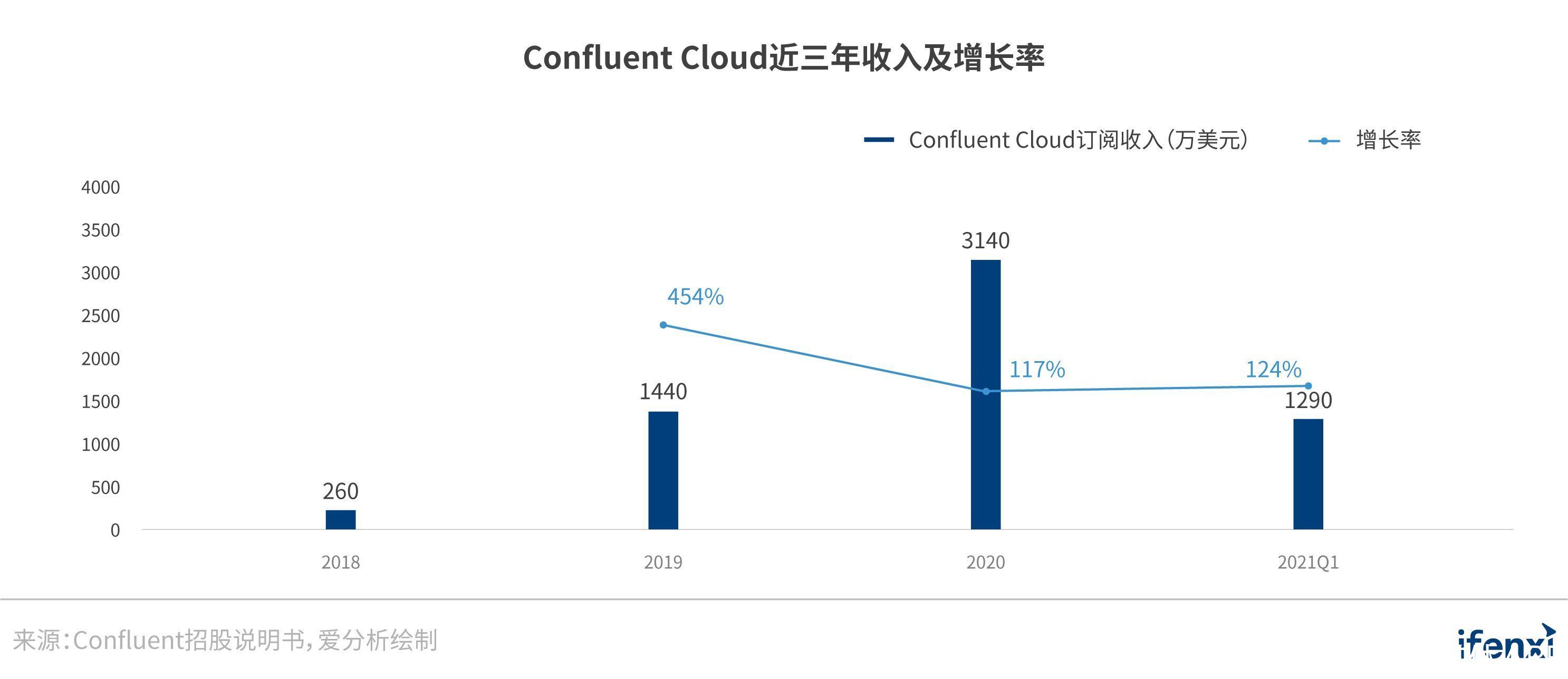
文章插图
在此之前,去年IPO、市值曾达800亿美元的明星大数据公司Snowflake,更是云原生的代表。Snowflake针对云计算环境将产品特性进行了深度优化,在云端向客户提供简单易用、弹性伸缩、按使用量计费的一站式数据管理和分析平台。其突出特征是支持计算、存储节点单独扩展,从而实现了资源的精细化管理,有效降低了扩容成本,同时可以做到按使用量付费。
- 华为|云计算的到来,在你身边有哪些相关联的。怎么看云计算呢(十九)
- 马云|马云自己\打脸\之前所说的,如今现身西班牙,开12亿游艇!
- 云厂商为什么都在冲这个KPI?
- 云计算|云计算的到来,在你身边有哪些相关联的。怎么看云计算呢(十五)
- 金山云|2000元的手机也搭载4nm芯片,为啥还要买四五千元的?看完明白了
- 嘉定这家专业用品市场推出“云逛店”模式
- 蚂蚁森林|马云承诺每年在沙漠里“种树”,如今6年过去了,现在怎么样了?
- 腾讯|微信上车碰壁,腾讯选择“云造车”
- “星云”纯电系统化平台首揭秘,上汽七大技术底座正加快落地
- 马云|马云消失半年后首次露面,奢侈生活现状曝光