中国科学院|AAAI 2022大奖出炉!中科院德州扑克程序AlphaHoldem获卓越论文奖( 二 )
但目前主流德州扑克AI背后的核心思想是利用反事实遗憾最小化(Counterfactual Regret Minimization, CFR)算法逼近纳什均衡策略。
具体来说,首先利用抽象(Abstraction)技术[3][7]压缩德扑的状态和动作空间,从而减小博弈树的规模,然后在缩减过的博弈树上进行CFR算法迭代。
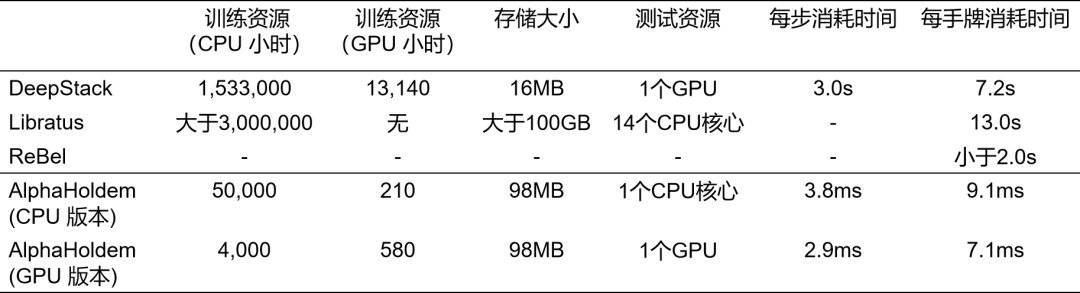
这些方法严重依赖于人类专家知识进行博弈树抽象,并且CFR算法需要对博弈树的状态结点进行不断地采样遍历和迭代优化,即使经过模型缩减后仍需要耗费大量的计算和存储资源。例如,DeepStack使用了153万的CPU时以及1.3万的GPU时训练最终AI,在对局阶段需要一个GPU进行1000次CFR的迭代过程,平均每个动作的计算需耗时3秒。Libratus消耗了大于300万的CPU时生成初始策略,每次决策需要搜索4秒以上。
这样大量的计算和存储资源的消耗严重阻碍了德扑AI的进一步研究和发展;同时,CFR框架很难直接拓展到多人德扑环境中,增加玩家数量将导致博弈树规模呈指数增长。另外,博弈树抽象不仅需要大量的领域知识而且会不可避免地丢失一些对决策起到至关作用的信息。
文章插图
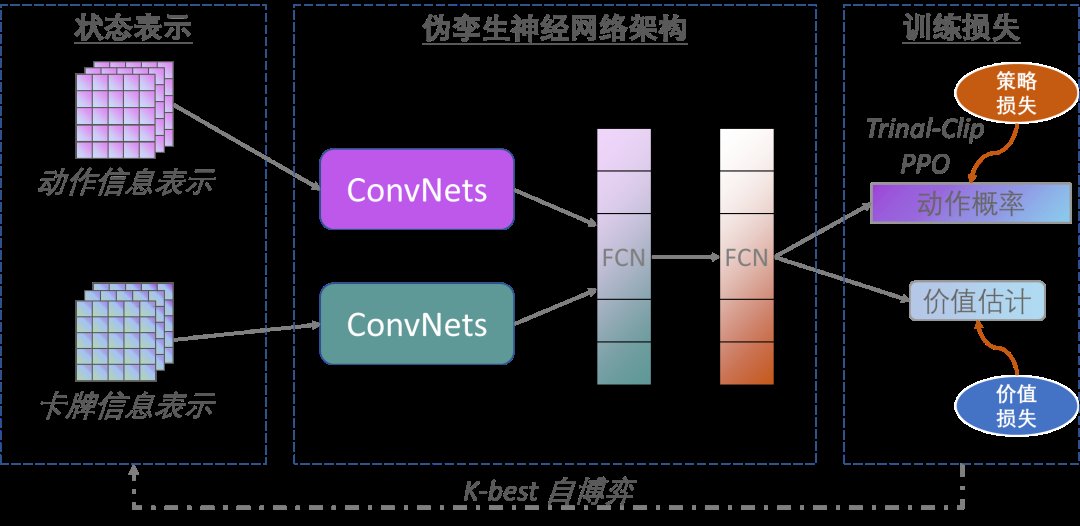
不同于已有的基于CFR算法的德州扑克AI,中科院博弈学习研究组所提出的架构是基于端到端的深度强化学习算法(如图4所示)。
文章插图
根据团队介绍,AlphaHoldem采用Actor-Critic学习框架,其输入是卡牌和动作的编码,然后通过伪孪生网络(结构相同参数不共享)提取特征,并将一种改进的深度强化学习算法与一种新型的自博弈学习算法相结合,在不借助任何领域知识的情况下,直接从牌面信息端到端地学习候选动作进行决策。
他们还指出,AlphaHoldem的成功得益于其采用了一种高效的状态编码来完整地描述当前及历史状态信息、一种基于Trinal-Clip PPO损失的深度强化学习算法来大幅提高训练过程的稳定性和收敛速度、以及一种新型的Best-K自博弈方式来有效地缓解德扑博弈中存在的策略克制问题。
AlphaHoldem 使用了1台包含8块GPU卡的服务器,经过三天的自博弈学习后,战胜了Slumbot和DeepStack。每次决策时,AlphaHoldem都仅用了不到3毫秒,比DeepStack速度提升超过了1000倍。同时,AlphaHoldem与四位高水平德州扑克选手对抗1万局的结果表明其已经达到了人类专业玩家水平。

文章插图

文章插图
兴军亮,中国科学院自动化研究所研究员、博士生导师、特聘青年骨干,中国科学院大学岗位教授,中国科学院人工智能创新研究院创新专家组专家。兴教授2012年毕业于清华大学计算机科学与技术系,获工学博士学位。
- 领军企业|30个!中国科协发布2022年科技领域重大问题难题
- |电饭煲哪个牌子好用质量好?2022年电饭煲排行榜前5名
- |2022上半年口碑不错的机型盘点,这几款2K价位中端机更香
- 鸢尾|2022下半年展望,iPhone14Pro领衔,5款重磅新机又将大放异彩
- 荣耀|2022下半年荣耀手机哪款值得入手?不必纠结,口碑已给出答案
- 荣耀x30|荣耀X30跌至千元机价格,2022年到底值不值得入手呢?
- 小屏|2022年坚持用小屏手机的用户,一般是这三类人,被说中了吗?
- iphone11|2022年最不值得买的三款手机,配置虽高但缺点明显,别花冤枉钱了
- 零售业|2022年全球物联网PaaS市场现状及发展趋势预测分析(图)
- 小米科技|2022年6月份:超值的5款平板电脑,华为轻松刷榜,小米屈居第四