文章插图
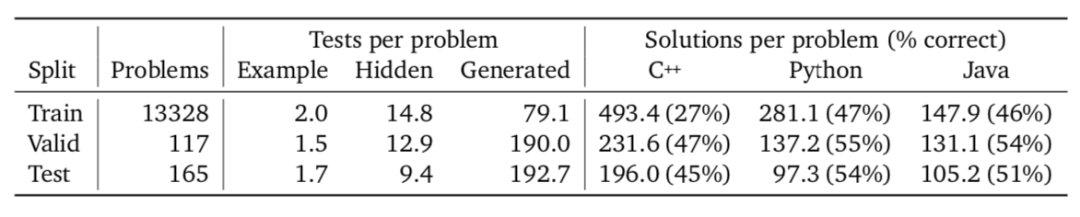
他们抓取了一些 github 代码,并随机选择所谓的枢轴点(pivot point)。
文章插图
枢轴点之前的所有内容都会被输入编码器,而解码器的目标是重建枢轴点以下的代码。
文章插图
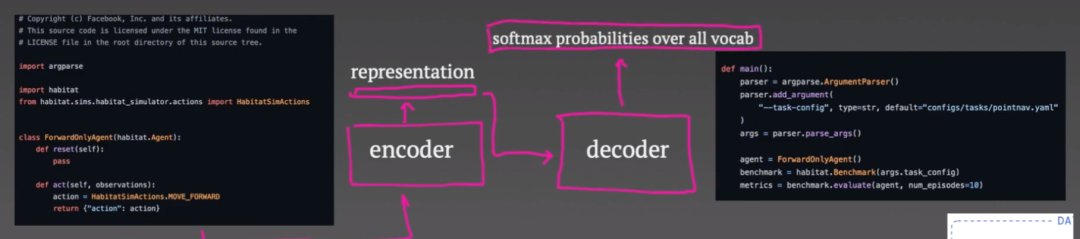
编码器仅输出代码的向量表示,可用于整个解码过程。
解码器以自回归方式运行:首先预测代码的第一个标记。然后,损失函数只是预测的 softmax 输出和真实令牌(token)之间的交叉熵。第一个真正的令牌会成为解码器的输入,然后预测第二个令牌,并且当要求解码器预测代码令牌的意外结束时,重复此过程直到代码结束。
现在,这些损失通过解码器和编码器反向传播,尽管事实证明:只为编码器添加第二个损失很重要。
这被称为掩码语言,可以高效地建模损失。将输入到编码器中的一些令牌清空。作为一种辅助任务,编码器尝试预测哪个令牌被屏蔽。一旦预训练任务完成,我们就进入微调任务。
在这里,我们将问题描述的元数据和示例输入投喂到编码器中,并尝试使用解码器生成人工编写的代码。这时,你可以看到这与编码器-解码器架构强制执行的结构非常自然地吻合,损失与预训练任务完全相同。
还有一个生成测试输入的Transformer。这也是从同一个 github 预训练任务初始化而来的,但它是经过微调来生成测试输入,而不是生成代码。
文章插图
文章插图
我们总是将元数据作为Transformer的输入。这包括问题的编程语言难度等级。一些问题的标签与解决方案在训练时是否正确?他们显然知道这些字段的值是什么,但是在测试时他们并不知道什么是酷炫的,那就是他们实际上可以在测试时将不同的内容输入到这些字段中以影响生成的代码。例如,你可以控制系统将生成的编程语言,甚至影响这种解决方案。
它尝试生成比如是否尝试动态编程方法或进行详尽搜索的答案。他们在测试时发现有帮助的是,当他们对 100 万个解决方案的初始池进行抽样时,是将其中的许多字段随机化。通过在这个初始池中拥有更多的多样性,其中一个代码脚本更有可能是正确的。
- 网友热议|母亲回应3个孩子2个上清华:只能教孩子做人诚实守信 学习都靠自己努力
- 生科医学|691分考生父母凌晨3点接到清华电话 本人淡定睡到早上:为家人要学医
- 学员分享:2022欧陆职位博士申请RoboticsCV方向一击即中波恩大学
- iPhone14|中科院:招博士后,研发7nm芯片技术
- 苹果|清华专家称苹果自乔布斯之后再无创新:跟以前没法比!
- 显卡|矿卡都影响科研了!南大博士高价买到50张1080Ti显卡研究癌症
- 京东|他是麻省理工的博士,被称为“中国互联网教父”,身价60多亿却58岁未婚
- 苹果多款产品有望支持 AV1 编解码器,代码已现身核心媒体框架库
- 师妹|博士开发出AI乳癌检测系统
- dji|复旦博士:重挫华为苹果成全球最大上市公司,亚洲科技王来自中国