vit|Meta AI发布图音文大一统模型Data2vec,CV精度超MAE
行早 发自 凹非寺
量子位 | 公众号 QbitAI
Meta AI搞了一个大一统的自监督学习模型Data2vec。
【 vit|Meta AI发布图音文大一统模型Data2vec,CV精度超MAE】怎么个大一统法?
图像、语音、文本都可以处理,效果还都不错,在CV方面甚至超过了包括MAE、MaskFeat在内的一众模型。
这是怎么做到的?我们来看看Data2vec的思路和结构。
Data2vec如何统一图音文关于这个问题,我们可以从模型名字中看出一些端倪。
和Word2vec把词转化为可计算的向量类似,Data2vec会把不同类型的数据都转化为同一种形式的数据序列。
这样就成功避开了模态不同这个问题。
然后,再用自监督学习的方法遮住这些数据的一部分,通过训练让模型把遮住的部分还原。
而它的结构也是在这个思路上设计的。
Data2vec以Transformer架构为基础,设计了一个教师-学生网络结构:

文章插图
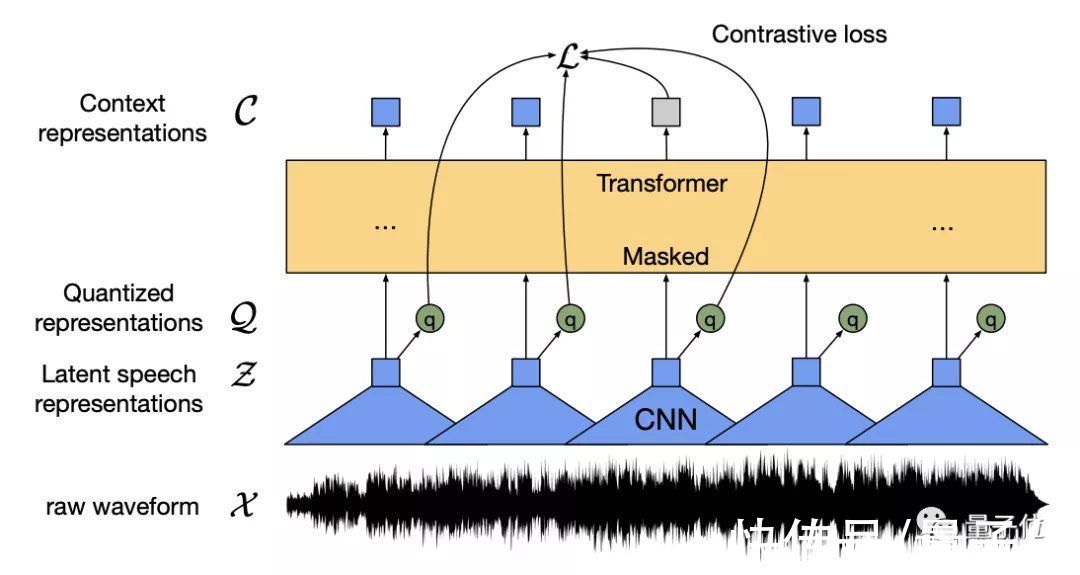
从上图中可以看出,无论对于任何形式的输入,都先转化为数据序列,并mask一部分信息(或挡住狗头,或覆盖一段语音,或遮住一个单词)。
然后让学生网络通过部分可见的输入去预测完整输入,再由教师网络去调整,达到一个模型处理多任务的效果。
那接下来的问题就是如何把不同类型的输入都转化为同一种形式了。
Data2vec如何标准化输入数据在标准化输入这一块,Data2vec还是具体问题具体分析的。
毕竟像素、波形和文本是完全不同的形式,而Data2vec对不同形式的输入采用了不同的编码策略,但是目的都是一样的。
那就是将这些输入都转化为数据序列。
具体的操作方法是这样的:
编码方式
掩码方式
计算机视觉
ViT图像分块
Block-wise Masking Strategy
语音
多层一维卷积神经网络
Mask spans of latent speech representation
文本
预处理获得子词单元,然后通过嵌入向量将其嵌入分布空间
Tokens
其中ViT的编码策略就是把一张图分成一系列的图块,每个图块有16x16个像素,然后输入到一个线性变换系统中。
而语音的编码方式是用多层的一维卷积神经网络将16kHz的波形转换为50Hz的一串数据序列。
文章插图
再加上文本编码的嵌入向量,这样所有模态的输入都转换为了数据序列,方便后续的训练。
而对于掩码策略来说,不同的模态的表现形式也是不一样的。
例如图像可以遮住一块,但是语音和文本有上下文的关联,不能随便遮住一部分。
因此对不同的模态,Data2vec也采取了相应的符合不同数据特征的掩码方式。
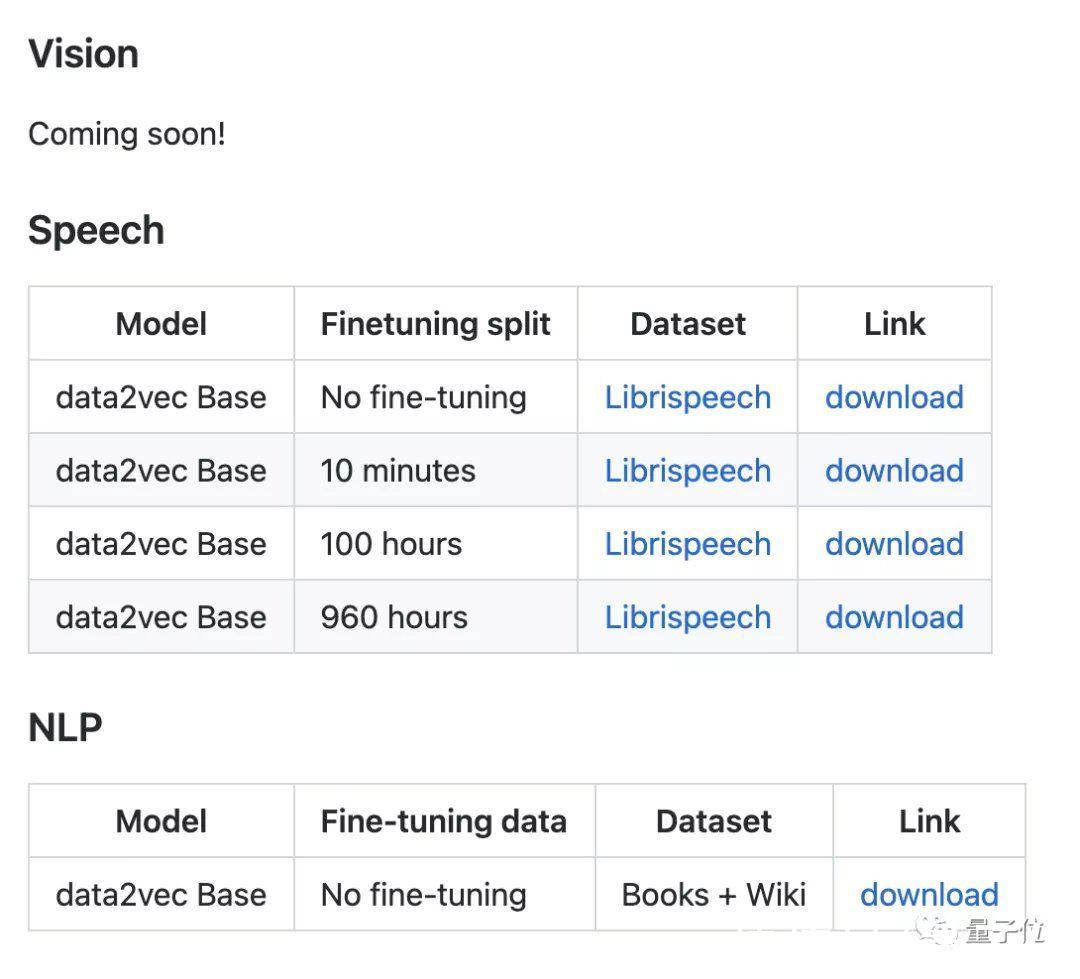
这样标准化之后,Data2vec还针对不同的下游任务做了一些微调,其中语音和文本的模型已经在GitHub上放出,视觉模型也正在路上:
文章插图
我们来看看这统一的模型性能怎么样。
性能表现虽然Data2vec三手齐抓,但是性能也没落下。
在计算机视觉方面,在IN1K上预训练情况如下表所示:
文章插图
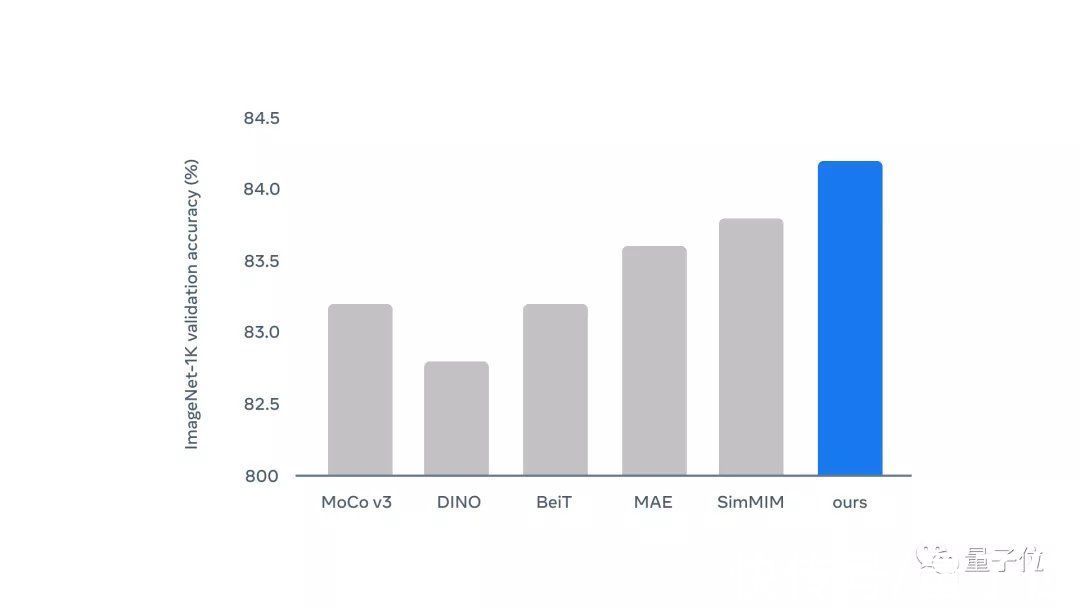
和一些其他模型相比,Data2vec精度表现最好。而且Data2vec只训练了800个epochs,而表中的MAE,MaskFeat训练了1600个epochs。
看柱状图则更为明显,蓝色为Data2vec:
文章插图
在语音处理方面,在LS-960上预训练结果如下:
- meta|促进更逼真AR/VR体验,Meta正在开发全新空间音频工具
- 领军企业|30个!中国科协发布2022年科技领域重大问题难题
- 小米|小米12S系列官宣7月4日正式发布:小米与徕卡联合研发
- 最前线 | 腾讯游戏发布40余款产品与项目,《王者荣耀》发布全新规划
- 腾讯游戏发布40余款产品与项目,《王者荣耀》发布全新规划
- 华为|重磅级新品官宣:华为全屋智能2.0将于7月4日发布 前代39999元起
- 口红|下周发布!华为P50 Pocket新版开启预订:送1699元口红耳机
- NVIDIA|GTX 1630最新发布时间曝光:6月28日 定价1000元
- gen.g战队|高通可能会在11月14日发布骁龙8 Gen 2 SoC,明年安卓机旗舰就看它了
- 腾讯|Reno8系列发布新色花仙紫:工艺全新升级,暑假换机还有限时礼盒