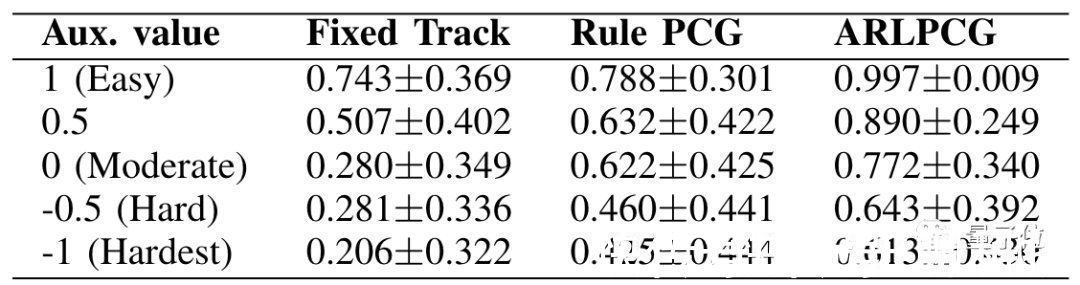
其中,对抗强化生成路径的通过率明显高于其他两种。
文章插图
此外,因为具有对未知环境泛化的能力,这个AI训练好后还可以被用于实时测试。
它可以在未知路段中构建出合理的通过路线,并能反馈路径中的障碍或其他问题的位置。

文章插图
此外,这个AI还能被用于不同的游戏环境,在这篇论文中,EA还展示了它在赛车游戏环境中的表现情况。

文章插图
在这个场景下,生成器可以创建不同长度、坡度、转弯的路段,解算器则变成了小车在上面行驶。
如果在生成器中添加光线投射,还能在现有环境中导航。
在这种情况下,我们看到生成器在不同障碍物之间创建行驶难度低的轨道,从而让小车到达终点(图中紫色的球)。

文章插图
为测试大型开放游戏论文一作Linus Gisslén表示,开放世界游戏和实时服务类游戏是现在发展的大势所趋,当游戏中引入很多可变动的元素时,会产生的bug也就随之增多。
因此游戏测试变得非常重要。
目前常用的测试方法主要有两种:一种是用脚本自动化测试,另一种是人工测试。
脚本测试速度快,但是在复杂问题上的处理效果不好;人工测试刚好相反,虽然可以发现很多复杂的问题,但是效率很低。
而AI刚好可以把这两种方法的优点结合起来。

文章插图
事实上,EA这次提出的新方法非常轻便,生成器和求解器只用了两层具有512个单元的神经网络。
Linus Gisslén解释称,这是因为具有多个技能会导致模型的训练成本非常高,所以他们尽可能让每个受过训练的智能体只会一个技能。
他们希望之后这个AI可以不断学习到新的技能,让人工测试员从无聊枯燥的普通测试中解放出来。
此外EA表示,当AI、机器学习逐渐成为整个游戏行业使用的主流技术时,EA也会有充分的准备。
论文链接:
https://arxiv.org/abs/2103.04847参考链接:
[1]https://venturebeat.com/2021/10/07/reinforcement-learning-improves-game-testing-ai-team-finds/
[2]https://www.youtube.com/watch?v=z7q2PtVsT0I— 完 —
【 g用上强化学习和博弈论,EA开发的测试AI成精了】量子位 QbitAI · 头条号签约
- One|基于Android 13打造:三星Galaxy S22抢先用上One UI 5.0
- 网友热议|母亲回应3个孩子2个上清华:只能教孩子做人诚实守信 学习都靠自己努力
- 运用元宇宙技术强化“汉字田园”建设的初步构想
- 格力电器|不要再说Python难了,按照这个学习路线,四周速成Python
- 小米科技|这台百元机也太值了吧!ColorOS 12新系统用上了
- 游戏本|不再是游戏本专属!轻薄本纷纷用上高刷屏,这些升级体验是关键
- OPPO|准大学生看过来!满足大学四年学习、生活需求平板,三件套不到2K
- 小米|曝小米中端机用上华星光电LTPO屏:效果比肩旗舰小米12 Pro
- OPPO|曝OPPO将下放马里亚纳X:realme、一加用上自研芯
- 京东|Java:有哪些快速学习Java语言的技巧?